PinnedKulasangar GowrisangarinAWS in Plain EnglishCreating and attaching an AWS IAM role, with a policy to an EC2 instance using Terraform scriptsWhat is Terraform?·4 min read·Sep 2, 2018--2--2
Kulasangar GowrisangarinITNEXTUsing Parameters in Inline Lambda Function Code within the Same CloudFormation TemplateIn this blog post I’ll explain how you can extract and use the values of Parameters in a CloudFormation template within an inline code of a…·3 min read·Jun 16, 2023----
Kulasangar GowrisangarinITNEXTRunning Hadoop through Cygwin on Windows and Copy/Browse files in HDFSIn this blog post, you’ll see how you can setup a pseudo-distributed, single-node Hadoop (any stable version) cluster backed by the Hadoop…·6 min read·Jun 8, 2023----
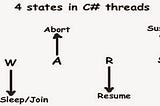
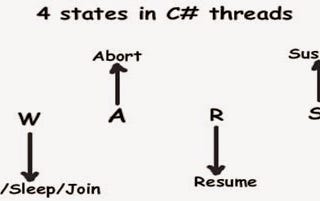
Kulasangar GowrisangarinITNEXTWhy do we need Wait() and Pulse() Methods in C# Threading?In this blog post, we’ll see how these two methods work in the threading world.·3 min read·May 15, 2023----
Kulasangar GowrisangarinNerd For TechExtracting a list of JSONs and Creating a Dataframe; with Milliseconds to Date format ConversionIn this blogpost we’ll see:·3 min read·May 4, 2023----
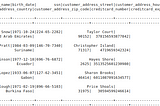
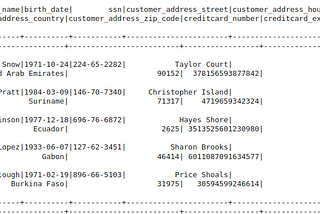
Kulasangar GowrisangarinLevel Up CodingUsing Python Faker library to generate dummy dataWhat is dummy data?·3 min read·Dec 26, 2022----
Kulasangar GowrisangarinGeek CultureStreaming Twitter Feed into Elasticsearch and MySQL using Apache NiFiIn this blog post I’ll be explaining on how we can easily extract Twitter feed, stream it into Elasticsearch in real time, analyze and…·7 min read·Jan 17, 2022----
Kulasangar GowrisangarinGeek CultureWhat is SchemaCrawler and Why would you need it?In this blog post, I’m going to explain how you can use Schema Crawler tool in order to bring in table details from a given schema. To keep…·5 min read·Jul 8, 2021----
Kulasangar GowrisangarinLevel Up CodingWhat is AWS Data Pipeline and how it can be used?I was listing down some of the AWS web services that I haven’t personally touched based on, and that’s when I tumbled upon AWS Data…·7 min read·Jan 23, 2021----
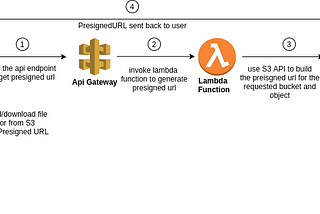
Kulasangar GowrisangarinLevel Up CodingUse Presigned URL to upload files into AWS S3In this blog post, I will be walking through the steps as to how we can utilize the presigned url feature to upload files into AWS S3…·4 min read·Oct 29, 2020--4--4